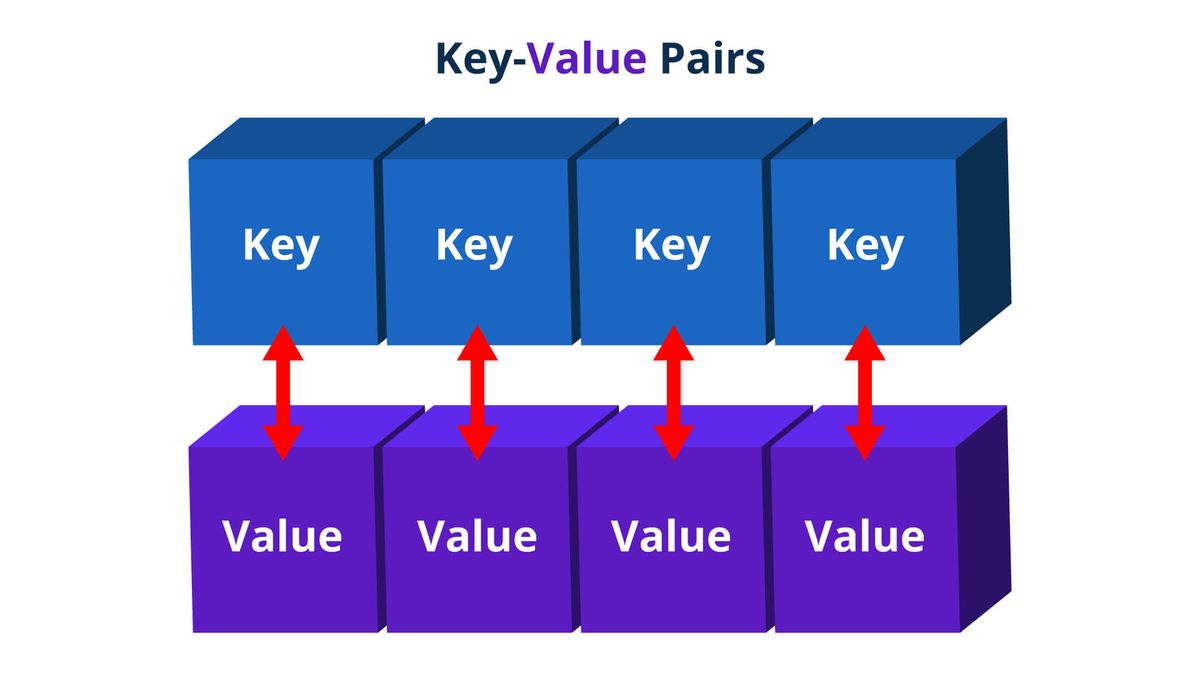
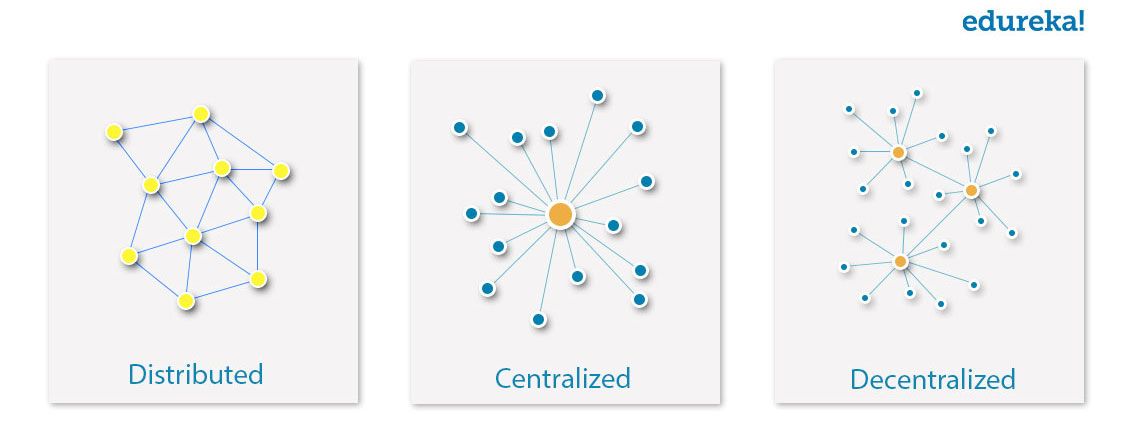
Hadoop-järjestelmänvalvojan vastuut
Tämä Hadoop-järjestelmänvalvojan vastuualueita käsittelevä blogi käsittelee Hadoopin hallinnon laajuutta. Hadoop-järjestelmänvalvojan työpaikoilla on suuri kysyntä, joten opi Hadoop nyt!

Tämä Hadoop-järjestelmänvalvojan vastuualueita käsittelevä blogi käsittelee Hadoopin hallinnon laajuutta. Hadoop-järjestelmänvalvojan työpaikoilla on suuri kysyntä, joten opi Hadoop nyt!
Apache Spark on tullut loistava kehitys suurten tietojenkäsittelyjen alalla.
Apache Hadoop 2.x koostuu merkittävistä parannuksista verrattuna Hadoop 1.x: ään. Tämä blogi kertoo Hadoop 2.0 Cluster Architecture Federationista ja sen komponenteista.
Tämä antaa käsityksen Job trackerin käytöstä
Apache Pigilla on useita ennalta määritettyjä toimintoja. Viesti sisältää selkeät vaiheet UDF: n luomiseksi Apache Pig -sovelluksessa. Tässä koodit kirjoitetaan Java-kielellä ja edellyttävät Pig-kirjastoa
Siellä HBase Storage -arkkitehtuuri sisältää lukuisia komponentteja. Katsotaanpa näiden komponenttien toimintoja ja tiedetään, miten tietoja kirjoitetaan.
Apache Hive on Hadoopin päälle rakennettu tietovarastopaketti, jota käytetään tietojen analysointiin. Hive on suunnattu käyttäjille, jotka ovat tyytyväisiä SQL: ään.
Huippuyhtiöiden toteuttama Apache Spark Hadoopin kanssa laajamittaisesti osoittaa sen onnistumisen ja potentiaalin reaaliaikaisessa prosessoinnissa.
NameNode High Availability on yksi Hadoop 2.0: n tärkeimmistä ominaisuuksista. NameNode High Availability with Quorum Journal Manager -sovellusta käytetään muokkauslokien jakamiseen aktiivisten ja valmiustilojen nimisolmien välillä.
Hadoop-kehittäjän työtehtävät kattavat monia tehtäviä. Työtehtävät riippuvat toimialueestasi / sektoristasi. Tämä rooli on samanlainen kuin ohjelmistokehittäjä
Hive-tietomallit sisältävät seuraavat komponentit, kuten tietokannat, taulukot, osiot ja ämpärit tai klusterit.Hive tukee primitiivisiä tyyppejä, kuten kokonaislukuja, kelluvia, tuploja ja merkkijonoja.
Nämä neljä syytä päivittää Hadoop 2.0: een puhuvat Hadoopin työmarkkinoista ja siitä, miten se voi auttaa sinua nopeuttamaan urasi tekemällä sinut avoimeksi valtaville työmahdollisuuksille.
Tässä blogissa käytämme Hive and Warn -esimerkkejä Sparkissa. Rakenna ensinnäkin Hive ja Lanka Sparkille, ja sitten voit käyttää Hive ja Lanka -esimerkkejä Sparkilla.
Tämän blogin tarkoituksena on oppia siirtämään tietoja SQL-tietokannoista HDFS: ään, kuinka tietoja voidaan siirtää SQL-tietokannoista NoSQL-tietokantoihin.
Cloudera -sertifioitu kehittäjä Apache Hadoopille (CCDH) on vauhti urallesi. Tässä viestissä käsitellään etuja, tenttikuvioita, opinto-opasta ja hyödyllisiä viitteitä.
Tämä blogi tarjoaa yleiskatsauksen HDFS High Availability -arkkitehtuurista ja siitä, kuinka HDFS High Availability -ryhmä asetetaan ja määritetään yksinkertaisilla vaiheilla.
Apache Kafka on edelleen suosittu reaaliaikaisen analyysin suhteen. Tässä on katsaus siihen uran näkökulmasta keskustelemalla uramahdollisuuksista ja työvaatimuksista.
Apache Kafka tarjoaa korkean suorituskyvyn ja skaalautuvat viestintäjärjestelmät, joten se on suosittu reaaliaikaisessa analytiikassa. Opi kuinka Apache kafka -opetusohjelma voi auttaa sinua
Tämä blogikirjoitus on syvällinen sukellus Possuun ja sen toimintoihin. Löydät esittelyn siitä, miten voit työskennellä Hadoopin kanssa Pigin avulla ilman Java-riippuvuutta.
Tässä blogissa käsitellään Hadoopin oppimisen edellytyksiä, Java olennaista Hadoopille ja vastauksia 'tarvitsetko Java oppia Hadoopia', jos tiedät Pig, Hive, HDFS.