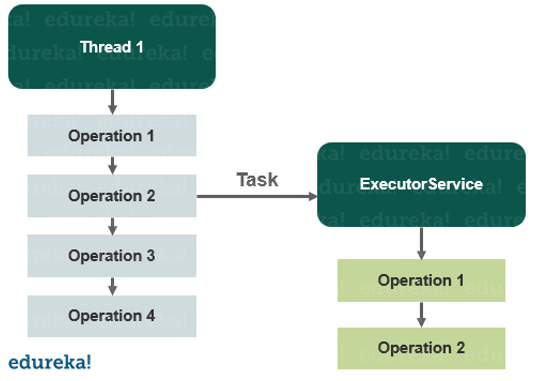
HBase-opetusohjelma: HBase-esittely ja Facebook-tapaustutkimus
Tämä HBase-opetusblogi esittelee sinulle, mikä on HBase ja sen ominaisuudet. Se kattaa myös Facebook Messenger -tapaustutkimuksen HBasen hyötyjen ymmärtämiseksi.

Tämä HBase-opetusblogi esittelee sinulle, mikä on HBase ja sen ominaisuudet. Se kattaa myös Facebook Messenger -tapaustutkimuksen HBasen hyötyjen ymmärtämiseksi.
Tämä blogi on opas Puppet Masterin ja Puppet Agentin asentamiseen. Se sisältää myös esimerkin Apache Tomcatin käyttöönotosta Puppet Tomcat -moduulilla.
Tämä blogi on vaiheittainen opas Apache Pig -asennukseen Linux-ympäristössä. Asennamme Apache Pig 0.16.0: n ja suoritamme sen eri tiloissa.
Tämä HBase-arkkitehtuurin blogi selittää HBase-tietomallin ja antaa käsityksen HBase-arkkitehtuurista. Se selittää myös HBasen eri mekanismit.
Tämä Hive-opetusblogi antaa sinulle perusteellisen tiedon Hive-arkkitehtuurista ja Hive-tietomallista. Se selittää myös NASAn tapaustutkimuksen Apache Hivesta.
Tämä Spark Streaming -blogi tutustuttaa sinut Spark Streamingiin, sen ominaisuuksiin ja komponentteihin. Se sisältää Sentiment Analysis -projektin, jossa käytetään Twitteriä.
Tämä Spark MLlib -blogi esittelee sinut Apache Sparkin Machine Learning -kirjastoon. Se sisältää Spark MLlib -ohjelmaa käyttävän elokuvasuositussysteemiprojektin.
Tämä GraphX-opetusblogi esittelee sinut Apache Spark GraphX -palveluun, sen ominaisuuksiin ja komponentteihin, mukaan lukien lentotietojen analysointiprojekti.
Tämä Apache Flume -opetusblogi selittää Apache Flumen perusteet ja sen ominaisuudet. Se esittelee myös Twitter-suoratoistoa Apache Flumen avulla.
Apache Sqoop -opetusohjelma: Sqoop on työkalu tietojen siirtämiseen Hadoop- ja relaatiotietokantojen välillä. Tämä blogi kattaa Sooopin tuonnin ja viennin MySQL: stä.
Apache Oozie -opetusohjelma: Oozie on työnkulun ajoitusjärjestelmä Hadoop-töiden hallitsemiseksi. Se on skaalautuva, luotettava ja laajennettava järjestelmä.
Big Data -sovellukset mullistavat organisaatioita ja auttavat heitä tekemään informatiivisempia liiketoimintapäätöksiä analysoimalla suuria tietomääriä.
Apache Spark on ottanut haltuunsa Big Data & Analytics -maailman ja Python on yksi helpoimmin käytettävissä olevista ohjelmointikielistä, jota teollisuudessa käytetään nykyään. Joten tässä tässä blogissa opimme Pysparkista (kipinä pythonilla) saadaksesi parhaan mahdollisen hyödyn molemmista maailmoista.
Tämä blogi keskittyy Apache Hadoop YARNiin, joka otettiin käyttöön Hadoopin versiossa 2.0 resurssien hallintaa ja työn ajoitusta varten. Se selittää YARN-arkkitehtuurin sen komponenteilla ja kunkin suorittamilla tehtävillä. Se kuvaa hakemusten jättämistä ja työnkulun Apache Hadoop YARNissa.
Tässä PySpark-opetusohjelman blogissa opit PSpark-sovellusliittymästä, jota käytetään Apache Sparkin kanssa työskentelyyn Python-ohjelmointikielellä.
Tässä PySpark Dataframe -opetusblogissa opit Apache Sparkin muutoksista ja toiminnoista useilla esimerkeillä.
Tämä Cloudera Hadoop -oppaassa oleva Edureka-blogi antaa sinulle täydellisen käsityksen erilaisista Cloudera-komponenteista, kuten Cloudera Manager, Paketit, Hue jne.
Tämä viesti kuvaa Hadoop- ja NoSQL-taitojen kysynnän kasvusta IT- ja muilla aloilla. Lue, kuinka Hadoop- ja NoSQL-taidot auttavat
Tässä blogissa käsitellään Hadoop-toteutuksen etuja, Hadoop-aloitteita, Hadoop pienissä ja suurissa organisaatioissa sekä Hadoop-koulutuksen etuja uralla.
Hadoopista on tullut kuuma taito hankittavaksi IT-piirissä, Hadoop-oppijoiden profiilien määrä kasvaa rajusti päivittäin.