Spark vs Hadoop: Mikä on paras Big Data Framework?
Tämä blogikirjoitus puhuu apache spark vs hadoop. Se antaa sinulle käsityksen siitä, mikä on oikea Big Data -kehys, jota voit valita eri tilanteissa.

Tämä blogikirjoitus puhuu apache spark vs hadoop. Se antaa sinulle käsityksen siitä, mikä on oikea Big Data -kehys, jota voit valita eri tilanteissa.
Tämä blogi auttaa sinua ymmärtämään, miten sbteclipse-laajennus asennetaan ja asennetaan vaiheittaisten ohjeiden avulla Scala-sovelluksen ajamiseksi Eclipse IDE: ssä.
Tämä blogiviesti selittää, miksi sinun on aloitettava Apache Sparkin käyttö Hadoopin jälkeen ja miksi Sparkin oppiminen hadoopin hallinnan jälkeen voi tehdä ihmeitä urallasi!
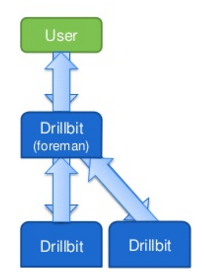
Tämä Apache Drill -opetusohjelma antaa sinulle kaikki tarvittavat tiedot Apache Drill -kyselymoottorin käytön aloittamiseen, käytön Hadoopin kanssa, Big Data & Apache Spark.
Tämä Spark Hadoop -blogi kertoo kaiken, mitä sinun tarvitsee tietää Apache Spark combByKeystä. Löydä keskimääräinen pisteet opiskelijaa kohden combybyKey-menetelmällä.
Apache Falcon on Hadoop-ekosysteemin uusi tiedonhallintafoorumi, joka yksinkertaistaa syötteen käsittelyä ja syötteen hallintaa hadoop-klustereissa. Opi määrittämään se.
Tämä Apache Spark -blogi selittää Spark-akut yksityiskohtaisesti. Opi Spark-akun käyttöä esimerkkien avulla. Kipinänakut ovat kuin Hadoop Mapreduce -laskurit.
Opi tästä Apache Flinkistä ja Flink-klusterin määrittämisestä tästä blogista. Flink tukee reaaliaikaista ja eräkäsittelyä ja on Big Data Analyticsin pakko katsella Big Data -tekniikka.
Tässä blogiviestissä käsitellään hajautettua välimuistia lähetysmuuttujien kanssa ja pääset aloittamaan suurten arvojen tehokkaan jakamisen Spark-ohjelmoinnissa.
Clouderan CCA- ja CCP-sertifikaatit ovat korvanneet CCDH- ja CCSHB-kokeet. Tämä blogi kertoo kaiken, mitä sinun tarvitsee tietää uusista sertifikaateista.
Tässä blogikirjoituksessa käsitellään tilanmuutoksia Spark Streaming -sovelluksen kanssa. Opi kaikki erien tietojen seurannasta tilakohtaisten D-streamien avulla.
Tässä blogiviestissä käsitellään Spark Streamingin tilanmuutoksia. Opi kaikki kumulatiivisesta seurannasta ja taitoja Hadoop Spark -uralle.
Hadoop & Big Data -tekniikat mullistavat terveydenhuollon analytiikan. Tämä iso data terveydenhuollon blogissa käsittelee kuinka big data -analytiikka voi parantaa lääketieteellistä hoitoa.
Tämä Hadoop Streaming -blogiviesti on vaiheittainen opas, jolla opitaan kirjoittamaan Hadoop MapReduce -ohjelma Pythonissa käsittelemään suuria määriä Big Data -tietoja.
Tämä Big Data Tutorial -blogi antaa sinulle täydellisen yleiskuvan Big Data -palvelusta, sen ominaisuuksista, sovelluksista sekä Big Data -palvelun haasteista.
Tämä HDFS-opetusblogi auttaa sinua ymmärtämään HDFS- tai Hadoop Distributed File System -järjestelmää ja sen ominaisuuksia. Tutki myös sen ydinkomponentteja lyhyesti.
Tässä Splunk-opetusohjelmassa ymmärrä Splunk vs. ELK vs.Sumo Logicin erot ja määritä, mikä näistä työkaluista sopii sinulle parhaiten.
Tässä Splunk-käyttötapablogissa ymmärrät, kuinka Domino's Pizza käytti Splunkia saadakseen oivalluksia kuluttajien käyttäytymisestä. Ja muotoile liiketoimintastrategiansa.
Tämä opetusohjelma on askel askeleelta -opas Hadoop-klusterin asentamiseksi ja sen määrittämiseksi yhteen solmuun. Kaikki Hadoop-asennusvaiheet koskevat CentOS-konetta.
Tässä blogissa kerrotaan erilaisista HDFS-komennoista, kuten fsck, copyFromLocal, expunge, cat jne., Joita käytetään Hadoop-tiedostojärjestelmän hallintaan.